
This video introduces the PF Interval: one of the core principles that underpins reliability centered maintenance and preventive maintenance program development.
Transcript
Hello, and welcome to this presentation about the PF interval. My name is Sandy Dunn, I’m the Managing Director of Assetivity and it’s my pleasure to give you this introduction to what is one of the key concepts that underpins reliability-centered maintenance and condition based maintenance.
So what is the PF interval? Well, as I said it is a key concept of reliability-centered maintenance. It is also:
- Core to determining what frequency you should perform a condition based maintenance inspection at.
- A term that was first coined by the late John Mowbray, the developer and author of the RCM II approach to reliability centered maintenance, and a man who I’m very fortunate to have been trained by in the United Kingdom in the early 1990s.
We say this is core to determining the frequency of condition based inspections, so what is a condition based maintenance inspection?
Well, it’s really an inspection or test to determine whether an item is about to fail, or is in the process of failing. A key requirement for us to be able to do a condition based maintenance inspection is that the item must give us some warning that it is about to fail. Fortunately for us, that’s very often the case – in fact most items give us some warning at least that they are about to fail, and some items actually give us multiple warnings that they’re about to fail.
For example, if we looked at a rolling element bearing, the warning signals that we might get from that bearing that tells us that it’s about to fail could include:
- high levels of vibration
- noise that is higher than we would normally expect to get from that bearing
- abnormally high temperatures
- an increased current draw on the motor (if the bearing is being driven by an electric motor)
- abnormal ultrasonic sound emissions
- smoke
We can plot those warnings on on a curve. If we take that bearing and we consider from when it’s running as-new until functional failure, we might find that, for example:
- vibration gives us a certain amount of warning before the bearing fails;
- noise gives us less warning that it’s about to fail;
- heat gives us less warning again; and
- smoke doesn’t give us very much warning at all – from when we see smoke coming out of the bearing until the bearing actually suffers its functional failure.
It’s important to realize that the bearing actually only suffers a functional failure when it ceases. There’s a temptation on some people’s part to say “we’ve got high vibration on the bearing, it’s failed”. Well actually no it hasn’t: the bearing is still rotating, the driver is still driving the driven item, the bearing is still fulfilling its function in almost all cases.
Therefore, the fact that we have hard vibration does not mean that the bearing has failed – what it does mean is that it’s about to fail. If we don’t do anything to avoid that failure, it doesn’t actually suffer the functional failure until a bearing has seized.
Our potential failure condition (a term that’s frequently used in reliability-centered maintenance) is a clearly identifiable condition that indicates that the functional failure is about to occur, that the bearing (in this case) is about to cease, or is in the process of ceasing. When we say “clearly identifiable,” what we mean is not just some vague term like “we’ve got high vibration” or “it’s running hot,” but what the specific temperature at which we would set an alarm level and say this bearing is about to fail – if we’re using heat as our potential failure condition.
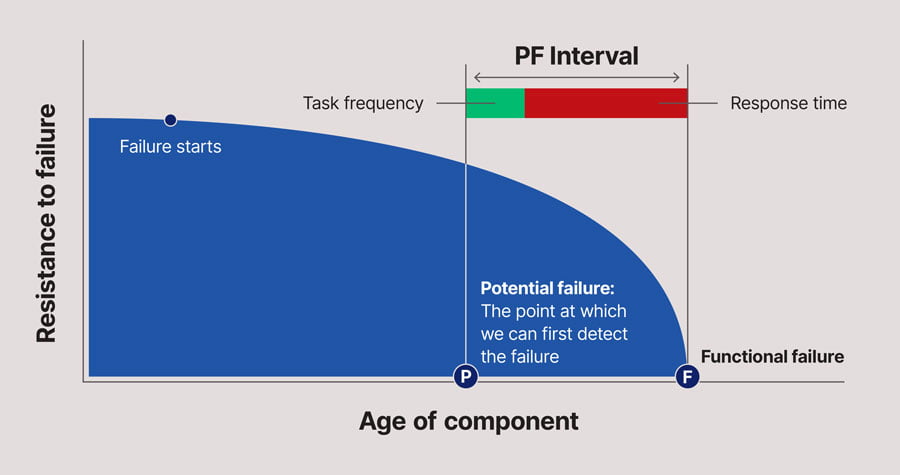
We need to be able to clearly identify and specify, as accurately as we can, what that potential failure condition is. In general what we’d find is that the point P on this curve is the point at which we can first detect that the item, in this case the bearing, is about to fail using that particular technique – for example heat – using the alarm level that we’ve set for that failure technique – for example 65 degrees Celsius, if that was the alarm temperature.
The point at which we could first detect that that bearing was running at 65 degrees Celsius or higher would be our point P on this curve. The point F then is the point at which we suffer a functional failure, in this case that the bearing has seized. The time interval between those is what we call the PF interval – the time interval from:
- When we can first detect the potential failure condition that the item is about to fail, using the particular technique and alarm level we’ve set; to
- The point which we suffer that functional failure.
Our condition based inspection, if we’re using that technique, for example heat and measuring the temperature of this bearing, must be done at some frequency that is less than the shortest likely PF interval for that particular technique. If we set the frequency of inspections to be greater than this PF interval, let’s say twice the PF interval, we might come along at this point and say “our temperature’s okay, the bearings okay, I can leave it in service – it’s not about to fail.” Then we come back later, and say “yep, this is hotter than it was before, but it’s still below my alarm level so I think the bearing is okay.” When we come back next: “whoops, I’ve gotten past the point at which we’ve suffered the functional failure,” and so therefore we’ve missed potentially predicting that that upcoming failure.
We must do the inspection at a frequency that’s less than the PF interval, but it’s not enough to be just less than the PF interval, it needs to be sufficiently less than the PF interval to allow us to avoid the consequences of the failure. If we inspected, for example, at exactly the PF interval, then I might do my inspection just before point P and say “oh it’s okay, it’s very close to my alarm level but it’s still okay,” then come back just before the bearing is about to cease, and that wouldn’t necessarily give me enough time to be able to avoid the consequences of the failure.
We need to be able to have our inspection interval at sufficiently less than the PF interval to be able to avoid the consequences of that failure.
The way of visualising that here is as follows: Let’s say that I have a certain amount of response time shown here as the red line on this graph – from when I can first detect that failure, it’s going to take me that long to get organized to avoid the consequence of the failure: take the piece of equipment out of service, for argument’s sake, or have a planned shutdown and do that work on that planned shutdown, without impacting on production. My task interval must be the PF interval minus that response time. In this case my task needs to be done at an interval that’s quite a lot less than the PF interval.
Now I know there’s rules of thumb around that basically say you know you should do this task of half a PF interval, that may or may not be appropriate, but I think it’s better to consider: “when I first detect this failure, how long is it going to take me to be able to respond in a planned manner, to avoid the consequences of the failure.”
If the response time is more than the PF interval, then you’ve got a problem – you know that particular technique clearly is not going to work for you and you will need to find another technique or way of predicting or preventing the failure.
To sum up, condition based inspections are appropriate when we do get some warning that the item is about to fail and we can specify that warning signal reasonably accurately, for example that temperature must be greater than 65 degrees Celcius. The PF interval is reasonably consistent for that alarm condition – for example, somewhere from a week to ten days for effective practical action. If you say “well sometimes it’s a day and sometimes it’s a month and I really can’t understand why it varies so widely,” this might not be a very reliable condition monitoring technique, and you might need to find another technique that’s more stable and predictable.
It needs to be practical to be able to perform the inspection at a frequency that is less than the PF interval – at the task interval. If you say for example: “we’ve got to do vibration analysis on this bearing every hour” then you might say “unless we’ve got permanently installed monitoring that’s really not going to be a practical outcome, so therefore we’ll have to find another type of task for for dealing with that particular failure mode”.
So that’s an introduction to the PF interval and and some of the key concepts that that it applies to. If you’re interested in learning a bit more about this, we do talk about this in a bit more detail in our Reliability Centered Maintenance and Preventive Maintenance Optimisation training courses. These public courses run around Australia and online, so if you’re interested you can have a look at our course schedule and and consider coming along to one of those – or we can run these courses in-house for you or your organisation if that’s a better option for you.
We can also provide consulting assistance in this space, if you’re looking to improve your preventive maintenance program through the use of reliability centered maintenance, that’s something that we have a lot of experience with. We’d be delighted to have the opportunity to help you.