
There is often confusion amongst those new to Maintenance and Reliability regarding the difference between Availability and Reliability. This article discusses the difference between the two, and also considers the relative importance of each when setting goals and targets for operational improvement. Let’s start with some basic definitions:
Availability
Availability is, in essence, the amount of time that an item of equipment or system is able to be operated when desired. It is most often expressed as a percentage, using the following calculation:
Availability = 100 x (Available Time (hours) / Total Time (hours))
For equipment and/or systems that are expected to be able to be operated 24 hours per day, 7 days per week, Total Time is usually defined as being 24 hours/day, 7 days/week (in other words 8,760 hours per year).
For equipment that is expected to be operated for lesser periods of time (for example, for a factory that only operates 12 hours per day, Monday to Friday), there is often debate regarding whether Total Time should still be defined as 8,760 hours per year, or whether it should be defined as the expected operating time (for the factory just mentioned, this would be 3,120 hours per year). The main difference, for practical purposes, is that if maintenance was performed during weekends, then this time would be counted as unavailable time using the first calculation, but would not impact on the availability calculation in the second example. There have been many hard-fought and passionate debates amongst experienced maintenance and reliability practitioners regarding which calculation is “correct”. Rather than enter into that debate here, I simply make two recommendations:
Whatever calculation you decide to use, make sure that it is documented, and that everyone within your organisation uses the same calculation. It is generally advisable to establish a standard “time model” with the relevant definitions and calculations to be used across your organisation. The time classifications, their definitions, and formulae for calculating ratios should all be driven by whatever makes sense for your organisation in assisting you to make better informed, more effective decisions. This may well be different for continuous processing industries compared with industries where discrete batch processing is more the norm. One example of a standard time model is illustrated below.
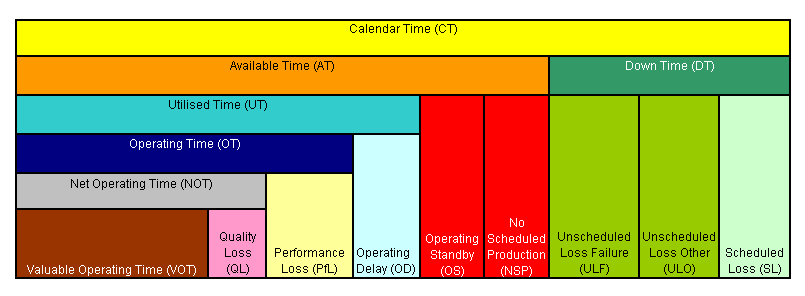
If you plan on benchmarking your “availability” with other organisations, make sure that you understand what definition(s) they are using for availability. If they are using a different definition for availability, then make sure that the necessary adjustments to the calculations are made before drawing any conclusions.
It is worth noting that there are some standardised definitions that exist for Availability – though not everyone uses them. One such measure is that adopted by the Society of Maintenance and Reliability Professionals (SMRP) in their Best Practices document. In addition, the European standard EN 15341:2007 (Maintenance – Maintenance Key Performance Indicators) also contains a definition for Availability (amongst others). The SMRP definitions have been harmonised with the definitions contained in the European Standard, with explanatory notes contained within the SMRP Best Practices Document.
Reliability
Reliability is defined as the ability of an item to perform as required, without failure, for a given time interval, under given conditions (http://tc56.iec.ch/about/definitions.htm#Reliability). It is most often measured by using the metric Mean Time Between Failure (MTBF), which is calculated as follows:
MTBF = Operating time (hours) / Number of Failures
Simplistically, Reliability can be considered to be representative of the frequency of failure of the item – for how long will an item or system operate (fulfil its intended functions) before it fails. We should also note that the reliability of an item can change over time. For example, items that have failure causes that become more prevalent as the items age will tend to show decreasing reliability as they become older.
If the difference between Availability and Reliability is still not quite clear to you, then ask yourself this question: the next time you jump on an aircraft to fly to another city, do you want the aircraft to have high levels of availability, or reliability? If you think about it, if the aircraft has poor availability, then this may have an influence on whether the plane departs (and therefore lands) on time. On the other hand, if the aircraft has poor reliability, then this may have an influence on whether the plane lands at all! Clearly, in this case, aircraft reliability (in terms of impact on safety performance) is more important than availability. But this may not necessarily be the same for other assets in other operating contexts. More on that later.
Availability vs reliability
So how (if at all) is Availability related to Reliability?
In terms of understanding the relationship between Availability and Reliability, let’s examine the elements that go to make up Availability. If you consider the time model illustrated above, you will see that Available Time is equal to Calendar Time minus Downtime. In turn, Downtime is made up primarily of two key components; Scheduled Downtime and Unscheduled Downtime. Scheduled Downtime could incorporate time scheduled for routine preventive maintenance activities or other scheduled operational activities (such as catalyst changes, product changes etc.) which mean that the equipment is not available. Unscheduled downtime will most likely be due to equipment failures, but could also incorporate downtime due to other unplanned/unscheduled events. The downtime that is associated with equipment failures will depend both on the equipment reliability (the number of equipment failure events) and the length of time that it takes to restore the functionality of the equipment each time one of these events occurs (typically measured by Mean Time to Repair – MTTR).
Using the above information, the formula for Availability transforms into the following:
Availability = 100 x (Calendar Time - Downtime) / Calendar Time
Availability = 100 x (Calendar Time - (Scheduled Downtime + Unscheduled Downtime)) / Calendar Time
If we assume that all unscheduled downtime is due to equipment failure events (just to make the calculation simpler for illustrative purposes), Unscheduled Downtime is then related to reliability via the following formula:
Unscheduled Downtime = MTTR x (Calendar Time - Downtime) / MTBF
From this we can see that:
- It is possible to have an equipment item with high reliability, but low availability if:
- Scheduled downtime is high (possibly due to excessively lengthy preventive maintenance) or
- MTTR is high (it takes a long time to repair each failure)
- Similarly, it is possible to have an equipment item with high availability but low reliability if:
- MTTR is low (each failure can be rectified quickly) or
- Scheduled downtime is low (e.g. no downtime is required for preventive maintenance)
More commonly, however, availability and reliability are linked, in the sense that if reliability increases, then availability can also be expected to increase, if all other elements in the calculations remain unchanged.
More to the story
However, the above calculations don’t tell the whole story. Let’s go back to the aircraft example that we discussed earlier. The impact of unreliability on the achievement of business goals may be much wider than just its impact on equipment availability or uptime. In the aircraft example, we saw that an unreliable aircraft may result in greater (possibly intolerable) safety risks. Indeed Ron Moore has collected data that shows a strong correlation between plant reliability and safety performance at a number of organisations. In addition, for complex process plants, even the shortest interruption to production due to a failure can cause significant additional losses to Overall Equipment Effectiveness as the plant is restarted, restabilised, and returned to full production with required product quality. These additional losses will not be captured if all that you measure is plant availability.
The situation is more complex for plant and equipment that is only required to operate intermittently. For example, the availability required for a machine that only operates 25% of the time may be quite low – but if the consequences of an in-service failure are high, then the reliability required may be high. Consider an emergency fire pump – what requirements should be placed on it in terms of availability and reliability? How would these requirements change if there was a second, redundant back-up fire pump installed?
Conclusion
I trust that this article has given you some insights and some food for thought. What are you measuring at your site? Availability, reliability, or both? And is the emphasis given to each of these measures appropriate for your organisation?
If you would like to receive early notification of future article publication, sign up for our newsletter now. In the meantime, if you would like assistance in development of a business case for your project, please contact us. We would be delighted to assist you.