
How are recent developments in areas such as big data, the internet of things, predictive technologies and predictive analytics impacting on traditional preventive and predictive maintenance activities? Where are these trends taking us, and what should maintenance organisations be doing now to take advantage of the opportunities that these technologies enable?
This article attempts to answer these questions. First, let’s start by defining some key terms.
What is big data?
Wikipedia describes big data as being “a broad term for data sets so large or complex that traditional data processing applications are inadequate. Challenges include analysis, capture, data curation, search, sharing, storage, transfer, visualization, and information privacy. The term often refers simply to the use of predictive analytics or other certain advanced methods to extract value from data, and seldom to a particular size of data set.” (https://en.wikipedia.org/wiki/Big_data). Immediately we see the conflict in this definition; the first sentence says that the data sets are large and complex, while the third sentence states that the terms is often used independent of the size of the data set.
For the purposes of this article, we will focus on “big data” as describing the large amounts of data that are available from disparate systems (such as ERP systems, process control systems, condition monitoring systems etc). The most important aspect of this, from a maintenance perspective, is that traditionally these datasets have been stored and analysed independently of one another. With the advent of the Internet of Things and other advances in information technology, we now have the capability to store and analyse a more complete picture of asset health, based on a more complete set of data drawn from a variety of sources.
What is the internet of things?
Put simply, the Internet of Things is the network of physical objects or “things” embedded with electronics, software, sensors, and network connectivity, which enables these objects to collect and exchange data. (https://en.wikipedia.org/wiki/Internet_of_Things). From an asset management and maintenance perspective, we have been fitting assets and asset systems with electronics and sensors for decades – think about flow indicators, pressure indicators etc. In the past, however, these sensors have been connected via proprietary communications protocols, and their outputs have usually only been available for viewing via a proprietary control interface, such as a Process Control System in a control room. With the advent of the Internet of Things, however, these devices can now communicate using standard internet communications protocols, using open standards, and as a result, the data is now potentially available to be used for a range of additional uses, beyond just process control, and is also potentially available to a much wider audience of users.
In addition, the ever-decreasing cost of electronics makes it increasingly more cost effective to fit equipment with a range of ever-more sophisticated sensors and processors which can do more than just measure a simple parameter (such as overall vibration levels), but can also do additional analysis and diagnostics on the machine (such as calculating RMS acceleration, true peak acceleration, compensated peak using bearing diameter and speed to normalize output, as well as other analysis. When these sensors are connected back to a communications backbone, this greatly increases the volume of data that is available for analysis, and also has the potential to enable real-time analysis.
What are predictive technologies and what is predictive analytics?
The terms Predictive Technologies and Predictive analytics are often used interchangeably. However, we would prefer to consider that Predictive Analytics is the analysis which is used to make predictions about unknown future events. Predictive analytics uses many techniques from data mining, statistics, modelling, machine learning, and artificial intelligence to analyse current data to make predictions about the future (http://www.predictiveanalyticstoday.com/what-is-predictive-analytics/). The key here is that there are a range of possible techniques that can be used to predict the future. In its simplest form, a simple rule that says that if bearing vibration exceeds a certain value, then the bearing is about to fail is a simple form of Predictive Analytics. However much more sophisticated predictive models are possible, and it is in this area that a lot of development is occurring.
In comparison, Predictive Technologies are the technologies that enable Predictive Analytics to occur. This could include the technologies which detect the initial warning signals that an event is about to occur (such as Vibration Monitoring technologies, Oil Analysis technologies etc) as well as the information processing technologies which are used to run the Predictive Analytics models.
What is preventive maintenance and what is predictive maintenance?
There are differing views on the definition of Preventive Maintenance and Predictive Maintenance depending on whether you apply the Reliability Centered Maintenance definitions or an alternative. Some people and organisations define Predictive Maintenance as being a particular subset of Preventive Maintenance, with both having the aim of preventing in-service failures of critical equipment.
For the purposes of this article, we will use the Reliability Centered Maintenance definitions, where:
Preventive Maintenance is a routine activity where components or equipment items are replaced or overhauled at a specific, pre-defined interval, regardless of their condition at the time, and
Predictive Maintenance is a routine activity to inspect or test for the presence of warning conditions that indicate that the item is about to fail. A corrective maintenance action is then scheduled (for completion at an appropriate future time) to replace, repair or overhaul the item before it suffers an in-service failure.
In this context we could consider replacement of the engine oil in a motor vehicle engine every 10,000km as being a Preventive Maintenance activity, while measuring the tread depth on the tyres would be a Predictive Maintenance inspection.
In general (most of the time but not always) Reliability Centered Maintenance prefers the use of Predictive Maintenance tasks to Preventive Maintenance tasks when determining an optimum Predictive and Preventive maintenance program. This is because (again, in general, and where technically feasible), Predictive Maintenance tasks maximise equipment uptime and component life by scheduling repairs and overhauls only when the equipment itself is telling us that this is needed, based on an assessment of equipment condition. There are exceptions to this general rule, but we will not explore this in detail in this article, in the interests of time and space. Instead, as a general rule, we consider that Predictive Maintenance provides better overall better business outcomes than Preventive Maintenance.
So what does all this mean? How do Big Data and the Internet of Things impact on our Predictive and Preventive Maintenance program? Let’s explore this by first outlining a conceptual model of the Predictive Maintenance process.
A model of predictive maintenance
In order to use Predictive Maintenance to avoid the consequences of in-service failures, the elements shown in Figure 1 below must be present in a Maintenance system.
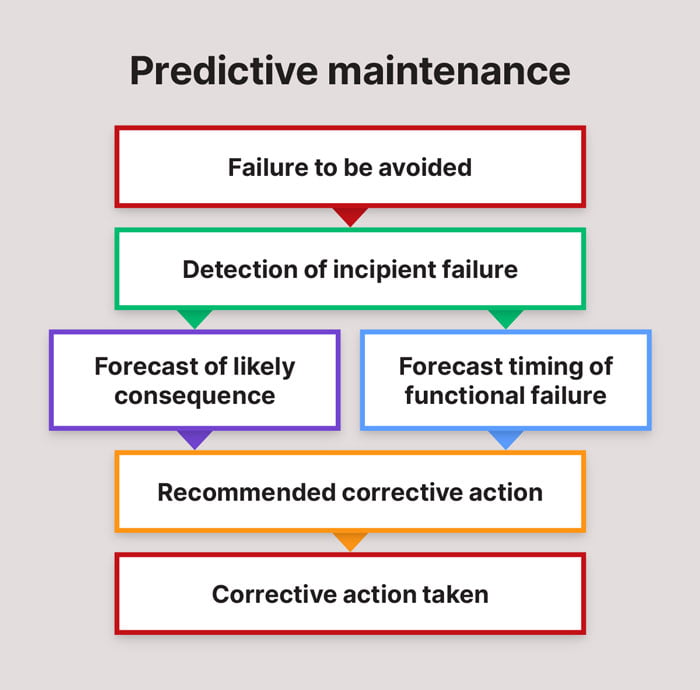
Let’s examine each of these elements, as they may be applied in a traditional Condition Monitoring program, and in a 21st century Maintenance program which makes use of the advances in Big Data, the Internet of Things and Predictive Analytics.
Failures to be avoided
The Failure to be Avoided is a specific failure event with an associated failure cause (failure mode), for a specific equipment item (or class of equipment). In both a traditional Condition Monitoring program and a 21st Century program, these are typically identified following some form of Failure Modes and Effects Analysis (FMEA), whereby the functions of an equipment item are identified, as well as the failure causes (failure modes) which may lead to loss of equipment function. This process may, or may not, be associated with formal Reliability Centered Maintenance (RCM) analysis. Note also that not all failure modes may be able to be predicted using predictive maintenance techniques. Some failure modes may give no warning of impending failure, others may give some warning, but the amount of warning given is insufficient to avoid the consequences of failure, and for others, the costs of detecting the impending failure may exceed the resulting benefits.
However, it is true for all Predictive Maintenance programs that, in order to establish an effective failure prediction system, it is essential that the failures causes (modes) that are to be avoided are known.
For failures that are to be avoided through the use of more advanced techniques (such as those that make use of complex data analysis and complex modelling techniques), the cost of developing and using these techniques means that, at present, in order to justify the funds required to develop and implement these complex technologies, the consequences must be significant. Preferably there should be a significant gap between the performance of any existing failure prediction or prevention strategies and those that may be achievable through the application of more advanced techniques. In other words, advanced predictive technologies need to be directed at the most significant opportunities to improve overall business performance – they must meet business needs, not just technical needs.
Detection of the incipient failure
Detection of the Incipient Failure consists of the measurement techniques, measurement data and supporting models that are able to detect and diagnose the existence of an incipient failure (a Potential Failure condition in RCM terminology). Traditionally, methods used have been mostly manual (periodic vibration analysis, oil analysis, human observations etc). In addition, traditional models used a single input (e.g. overall vibration level) with a single alarm level to detect incipient failures.
In a 21st century maintenance system however, the capabilities of big data and more sophisticated predictive analytical techniques allow us to analyse and synthesise a much greater quantity of data (for example, process data such as temperatures, pressures etc., or environmental data such as ambient temperature, rainfall etc). Multiple variables, often from disparate sources, can now be used as inputs for inclusion in models which detect the existence of incipient failures. And this data does not necessarily need to be numerical. Work is being done to permit the analysis of written text from logsheets and inspection sheets, so that the existence of certain keywords in these documents can be used as inputs into these predictive models. As one example, rather than simply using a predictive model that solely relies on the results of engine oil analysis to determine whether the engine is about to fail (and the risk that a very high reading could be misdiagnosed as a “bad sample”, it would be possible to correlate the results of the oil analysis, with recent engine fuel consumption (either from the onboard engine monitoring system, or from data obtained from the fuel bowser) and with reports of increasing levels of exhaust smoke recorded in a logbook to give an increasingly accurate picture of the existence of a potential failure condition.
There are a number of Predictive Analysis techniques that can be used to determine the variables, combinations of variables, and alarm levels to predict equipment failures. These range from the most simple, such as personal experience (I know that when smoke starts coming out of the bearing, then it is about to fail!), through to combined learned experience (based on our collective experience, we know that vibration levels greater than 9mm/sec on this pump bearing indicate that it is about to fail), and on to more sophisticated mathematical techniques. The most common of these techniques, which draw on the availability of Big Data, include:
- Regression techniques. These use various forms of statistical analysis, from simple linear regression models to multivariate adaptive regression models in order to predict that equipment failure is about to occur.
- Machine learning techniques. Put very simply, these emulate the way that humans learn by detecting patterns amongst variables that have, in the past, led to equipment failure, and then using pattern recognition techniques to identify situations similar to those that have occurred in the past.
The main differences between these are that regression techniques typically require you to formalise the relationships between your input variables in the form of a mathematical equation. On the other hand machine learning is an algorithm that can learn from data without relying on rules-based programming. For a more detailed explanation of the differences, there is a good article at http://www.analyticsvidhya.com/blog/2015/07/difference-machine-learning-statistical-modeling/.
However a common issue with all forms of predictive analytics, when it comes to predicting equipment failure, is that we actually need to have failure data to analyse. Most organisations, particularly when it comes to critical assets, tend not to allow these assets to run to failure – for obvious reasons. As a result, the best that we can do is to obtain data that relates to “suspended” failures – we replaced/overhauled/repaired the asset before it failed, so we know something about it – it lasted to that point in time without suffering a functional failure – but we do not know how much longer it would have continued to function if we had not intervened at that point of time. So a shortage of accurate, available data to be able to populate and test these mathematical analytical models which may predict equipment failures is a limitation which needs to be overcome.
Nevertheless, most of the current modelling effort, when it comes to big data and predictive analytics in the maintenance space, is currently focused on developing more sophisticated and accurate models to predict the existence of incipient failures.
In addition, more and more of this data is available in real-time, via equipment items fitted with an ever-increasing range of sensors, and which are increasingly connected to other system via the Internet of Things. Further, the models used to detect the existence of incipient failures are also developing at increasing rates. These days, techniques such as multivariate statistical analysis and machine learning, which use a number of inputs, can be used to develop more sophisticated models for detecting incipient failures. Frequently “Big Data” can facilitate the development of these models.
Forecasting the likely consequence
Once you understand that an equipment failure is in its early stages of development, Forecasting the Likely Consequence is important in order to ensure that the correct decision is made regarding how to proceed. At present, it is generally assumed that the consequence of each incipient failure, were it allowed to progress to functional failure, is fixed, and is therefore predetermined. However, in practice, for any single failure event, there is a range of possible consequences of that failure, and these can change over time. For example, high wheel bearing temperature on a train could either lead to the bearing seizing, with subsequent damage to the wheel and track, or it could lead to bearing collapse and potential derailment. Further, the consequences of this could vary depending on where the train happened to be located at the time of the bearing failure, and whether the train was loaded or unloaded. As another example, high bearing temperature on a conveyor drive motor feeding a shiploader will have different consequences depending on how much time remains before the ship is completely loaded, and the length of the break between the ship that is currently being loaded and the next ship that will require to be loaded.
In a traditional maintenance system, we record a single value for asset criticality – and, once established, it rarely changes. However in a future, 21st century maintenance management system, the criticality of an asset will be able to be updated constantly, in real time, using inputs from a range of different systems – such as production planning systems, process control systems, reliability/capacity models of production processes, sales and marketing systems, as well as real-time asset condition data obtained via the Internet of Things. Based on this real-time assessment, we will be much more able to fully understand the potential business implications and consequences of an individual incipient failure, and make a more informed decision regarding the corrective action to be taken, and the urgency with which it should be executed.
At present, there is much less work being done in this space. More work is being done to develop more sophisticated methods of identifying whether an incipient failure exists, in a technical sense, but not a lot of work being done to develop more sophisticated methods of deciding whether this incipient failure matters in terms of the likely business outcomes. However, over time, I expect that this will be a growing area of interest.
Forecasting the timing of a functional failure
Once we have established that an incipient failure (Potential Failure condition) exists on an asset, and that the consequences of a Functional Failure mean that this Functional Failure should be avoided, if possible, the next question that arises is “How long have we got before we will suffer this Functional Failure?”, or more precisely, “How long have I got before I need to do something to the equipment to prevent this Functional Failure from occurring?” This is where we enter the realm of prognostics, and advances in Predictive Technologies and Big Data may be able to assist in better answering this question.
At present, as those who are familiar with Reliability Centered Maintenance (RCM) will know, one of the key pieces of information we need to know in order to avoid the potential consequences of a Function Failure is the PF Interval (illustrated in Figure 2 below) – that is, the time interval from the point P (the point at which we can first detect the existence of the Potential Failure condition (or incipient failure) and the point F (the point at which we suffer the Functional Failure).
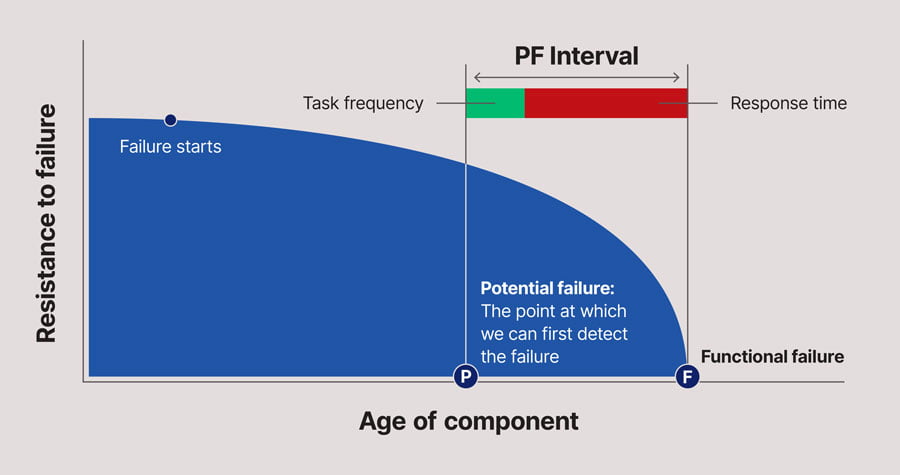
The PF Interval is important for two reasons.
The first is that, if we are conducting periodic inspections of asset condition, then we need to perform these at a frequency that is less than the PF Interval – indeed sufficiently smaller than the PF Interval to allow us to be able to take the necessary corrective action to avoid the consequences of the Functional Failure before the Functional Failure actually occurs.
The second is that the PF Interval tells us how quickly we need to take the necessary corrective action in order to prevent the Functional Failure from occurring.
Note that the advent of the Internet of Things, whereby more and more equipment condition parameters are being reported in real time, rather than via periodic inspection, allows us to select Potential Failure conditions (the point P in Figure 2) that are closer to the Point F while still being able to avoid the consequences of failure. This allows us to have a much more “just in time” approach to failure prevention, thereby extending component life. This is particularly the case with mobile equipment, such as mining haul trucks and road-going trucks, where the time interval between periodic conventional inspections can be quite large. Many of the reported benefits of the Internet of Things relating to vehicles actually are due to this factor alone. See https://hbr.org/2014/11/finding-the-money-in-the-internet-of-things for more discussion of this.
So how do we determine what the PF Interval actually is? At present, most organisations estimate the PF interval (except perhaps for highly critical failure modes) by using estimates from experienced maintainers and operators. This is often obtained in workshops by asking questions such as “How long will it take from when the bearing sounds noisy until it finally seizes?” Given that these estimates are likely to be inaccurate, often a conservative approach is taken, and the PF Interval is assumed to be lower than the group consensus (or the inspection is performed at a frequency considerably higher than the estimated PF Interval would suggest is required).
Predictive Analytics, combined with real-time condition monitoring enabled by the Internet of Things, however, may be able to allow us to estimate the PF Interval with more accuracy, by collecting information about how measured equipment condition changes over time during the PF Interval period. Further, Big Data may allow us to determine the additional factors that may influence what the PF Interval actually is, for a given failure mode, on a specific piece of equipment, under specific conditions. For example, by measuring the electrical load on an electric motor, and combining this with information about bearing vibration levels, we may be able to determine the impact that load on the motor has on the rate of deterioration from the point P to the point F.
As was mentioned earlier when discussing methods for determining the existence of Potential Failure conditions, however, a major limitation with more sophisticated Predictive Analytic techniques is the availability of sufficient failure data to accurately predict the PF Interval. In practice, we rarely allow the equipment to reach the point F – because the consequences of doing so are too great. Without that data, we need to make some assumptions based on the “suspended” failure data, as mentioned earlier.
Recommending a corrective action
The next step, now that we know that an asset is in the process of failing, we understand what the business consequences are if that asset was to fail while in service, and we know how long we have before the asset will fail, is to determine the most appropriate corrective action to be taken. For example, for our conveyor motor example we mentioned earlier, imagine that we had a shipping window opening up in 10 days’ time, and we could successfully change out the conveyor drive motor during that window with no impact on production. However, our modelling tells us that there is a 30% chance that the bearing will fail within the next 10 days. Alternatively, we have a smaller shipping window available in 2 days’ time, but we will need to delay loading the next ship by 4 hours in order to complete the motor replacement. Which action would you choose?
The short answer, in most current organisations, is that there is no formal, analytical process in place for making this decision. If you are highly risk averse, you would be likely to select the second option. If you were a bit more of a risk taker, then you may choose the first one.
In a 21st century maintenance organisation, however, we would use the better information that we have as a result of Big Data, Predictive Analytics and the associated models to make a much more informed decision regarding the most appropriate course of action.
Of course, this represents a major cultural shift in most organisations. Traditionally, we have left these decisions up to specific individuals, and their pride and feeling of self-worth often revolves around making these “big calls”. And these decisions are generally made spontaneously and without a lot of analytical forethought. Interposing a structured decision making process, with associated decision support tools into this process will represent a major change in thinking and in culture in many organisations.
Executing the recommended corrective action
Finally, knowing that an equipment item is about to fail, and making a decision about what to do to avoid the consequences of that failure is of little value unless the appropriate action to either avoid or mitigate the consequences of the failure is actually taken in a timely manner. Once again, this represents a major cultural shift in many organisations. At present, Condition Monitoring technicians in many organisations and in many industries will be able to regale you with many stories about the time that they told the maintenance execution team that an asset was about to fail, and recommended an appropriate course of action, only to find that their advice was either ignored completely, or was overlooked until it was too late, and the asset failed in service in any case.
In a 21st century Maintenance program, our Maintenance Management system and our Predictive Analytics systems will be integrated. If our models tell us that a corrective action has to be taken before a specific date, then this will be reflected in the due dates for the work order in our Maintenance Management system. Overdue and imminent corrective actions will be able to be flagged and monitored. The Maintenance Execution team will not be able to change these due dates, and they will ignore them at their peril – in theory at least!
The game changer: internet of things, big data and predictive analytics.
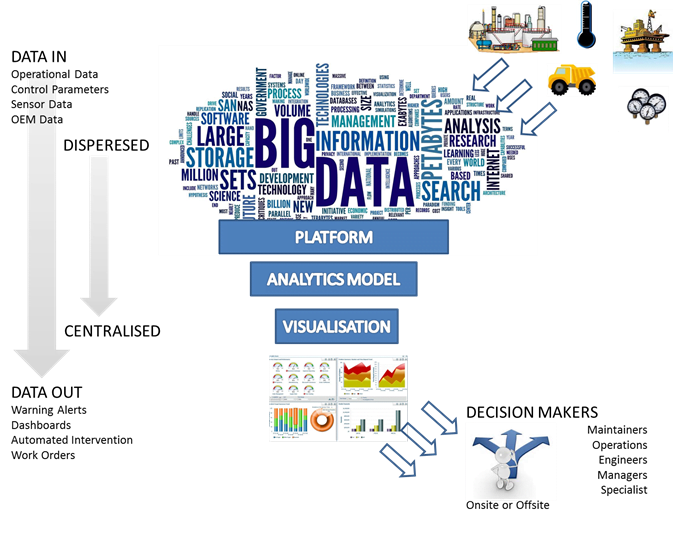
So we can see that the Internet of Things and Big Data represent, potentially, a huge opportunity to improve equipment reliability and reduce maintenance costs. In the past, the biggest roadblock that has existed for online condition monitoring is how to get the information from the equipment for analysing. The advent of cheap wireless technologies now means that where once sensors would have needed to be hard wired, a costly exercise, information can now be transferred wirelessly. Coupled with applications such as the Internet of Things, machine-to-machine interfaces, Clouds and server capacity, large volumes of information, or ‘Big Data’, can be shared quickly.
With significant continued investment in the fields of sensor design and predictive failure modelling platforms, what these technologies can deliver continues to grow. With inputs from sensors, actuators, control parameters and operational data from data historians such as SCADA, predictive technologies, as shown in Figure 2, can provide
- Visual Data exploration
- Dash boards
- Operation warnings
- Automatic Intervention
- Predictions on when the equipment will fail
In some cases, information can be captured within the CMMS system to complete the cycle.
Systems designed to achieve automated predictive maintenance claim the benefits as being
- Increased asset reliability
- Shortened maintenance times
- Improved uptime percentage
- Boost to Safety and Quality
- Early detection of minor disturbances
- Reduced maintenance costs
- Verification of developing fault from more than one data source
- Automated diagnostics reduces burden on maintenance staff
- Some systems claim to be able to predict remaining machine life
- Improve Root Cause Analysis
- Remote Access to Data
Predictive analytics and maintenance: the challenges
Successful implementation of predictive maintenance can be linked to two key areas explored in Table 1.
- Organisational – integrated approach across all levels of the organisation.
- Model/data sufficiency – models need to balance accuracy and stability to yield high data quality.
| Organisational | Model / Data Sufficiency |
|---|---|
| Trust in Information | Lack of Data |
| Expense | Data Quality/Integrity |
| Establishing Benefits of Predictive Maintenance Program | Data Volume |
| Priority conflict between departments (IT and Operations | Model Usability |
| Resourcing – Specific skill set required | Model Complexity |
| Implementation/Integration – impact on process and behaviours | Data Security |
Case study: Typhoon fighter jet maintenance
Finally, let us explore one case study where Big Data, the Internet of Things and Predictive Analytics claim to have delivered measurable benefits.
The objectives of the Typhoon Fighter Jet Maintenance program were to:
- Reduce cost and backup inventory of aircraft maintenance
- Maximise aircraft uptime
The expected benefits were a $3.1 Billion dollar maintenance saving over 25 years on 10 aircraft
Predictive Modelling techniques were used to predict component failures. The failure rates of aircraft components change with changing operating conditions, just as inventory requirements are dependent on air base locations. In all, 2000 components on each aircraft are simulated for wear, with each simulation generating a 40 megabyte output file that becomes the input for the next run of the model. Predictive modelling runs various iterations of the model to predict the effect of trends and changes in environment.
The stated outcomes of this program include:
- Identified capacity constraints within maintenance, ahead of time, so new plans can be put in place.
- Modelling has enabled data driven decisions about where maintenance is conducted to be optimised either on site or back in the UK.
- Aircraft uptime has increased, for example, aircraft on ground awaiting spares downtime has improved from double digits to 4%.
For more information, see http://data-informed.com/predictive-models-guide-fighter-jet-maintenance-for-raf-squadron/
Conclusion
Given technology advances, challenging operating conditions, possible return on investment and the opportunities that data sharing presents, Big Data, the Internet of Things and Predictive Analytics are currently more than feasible when applied to maintenance, and represent a huge potential opportunity for benefit for those organisations who are ready and able to take advantage of these technologies. The field is still in its infancy, and much work needs to be done to uncover the full potential that these technologies represent, but forward thinking organisations need to consider how they will get involved in developing and implementing these techniques in their organisations.
This article has only discussed the use of Big Data, the Internet of Things and Predictive Analytics to predict equipment failures. These technologies can also be used, not just to predict incipient equipment failures, but to eliminate them as well. That is potentially an even more exciting prospect, but is a topic for another article.
If you are interested in discussing the contents of this article, feel free to contact me, or join in the discussion on LinkedIn.